聚合
聚合框架有助于基于搜索查询提供聚合数据。它基于称为聚合的简单构建块,可以组合以构建复杂的数据摘要。
聚合可以被视为在一组文档上构建分析信息的工作单元。执行的上下文定义了该文档集的内容(例如,顶层聚合在搜索请求的执行查询/过滤器的上下文中执行)。
有许多不同类型的聚合,每个聚合都有自己的目的和输出。为了更好地理解这些类型,通常更容易将它们分为四个主要族:
-
Bucketing
构建存储桶的一系列聚合,其中每个存储桶与密钥和文档标准相关联。执行聚合时,将在上下文中的每个文档上评估所有存储桶条件,并且当条件匹配时,文档被视为“落入”相关存储桶。在聚合过程结束时,我们最终会得到一个桶列表 - 每个桶都有一组“属于”它的文档。
-
Metric
在一组文档中跟踪和计算指标的聚合。
-
Matrix
一系列聚合,它们在多个字段上运行,并根据从请求的文档字段中提取的值生成矩阵结果。与度量标准和存储区聚合不同,此聚合系列尚不支持脚本。
聚合其他聚合的输出及其关联度量的聚合
接下来是有趣的部分。由于每个存储桶有效地定义了一个文档集(属于该存储桶的所有文档),因此可以在存储桶级别上关联聚合,并且这些聚合将在该存储桶的上下文中执行。这就是聚合的真正力量所在:聚合可以嵌套!
![]()
分组聚合可以具有子聚合(分段或度量)。将为其父聚合生成的桶计算子聚合。嵌套聚合的级别/深度没有硬性限制(可以在“父”聚合下嵌套聚合,“父”聚合本身是另一个更高级聚合的子聚合)。
![]()
聚合操作double数据的表示。因此,当在绝对值大于的long上运行时,结果可能是近似的2^53。
结构化聚合
以下代码段捕获了聚合的基本结构:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
JSON中的aggregations对象(aggs也可以使用密钥)保存要计算的聚合。每个聚合都与用户定义的逻辑名称相关联(例如,如果聚合计算平均价格,则命名它是有意义的avg_price)。这些逻辑名称还将用于唯一标识响应中的聚合。每个聚合都有一个特定的类型(<aggregation_type>在上面的代码片段中),通常是命名聚合体中的第一个键。每种类型的聚合都定义了自己的主体,具体取决于聚合的性质(例如avg特定字段上的聚合将定义将计算平均值的字段。在聚合类型定义的同一级别,可以选择定义一组其他聚合,但这只有在您定义的聚合具有分支性质时才有意义。在此方案中,将针对由分组聚合构建的所有存储桶计算您在分段聚合级别上定义的子聚合。例如,如果在聚合下定义一组range聚合,则将为定义的范围存储桶计算子聚合。
值源
某些聚合适用于从聚合文档中提取的值。通常,将从使用field聚合密钥设置的特定文档字段中提取值。也可以定义一个 script将生成值(每个文档)。
如果为聚合配置了两者field和script设置,则脚本将被视为a value script。虽然在文档级别评估普通脚本(即脚本可以访问与文档关联的所有数据),但是在值级别上评估值脚本。在此模式下,从配置中提取值,field并script用于对这些值应用“转换”。
![]()
使用脚本时,还可以定义lang和params设置。前者定义了所使用的脚本语言(假设Elasticsearch中有适当的语言,默认情况下或作为插件)。后者允许将脚本中的所有“动态”表达式定义为参数,这使脚本能够在调用之间保持静态(这将确保在Elasticsearch中使用缓存的编译脚本)。
Elasticsearch使用映射中字段的类型来确定如何运行聚合并格式化响应。但是有两种情况,Elasticsearch无法找出这些信息:未映射的字段(例如,跨多个索引的搜索请求,只有部分字段具有该字段的映射)和纯脚本。对于这些情况,可以使用该value_type选项为Elasticsearch提供一个提示,该选项接受以下值:string,long(适用于所有整数类型), double(适用于所有小数类型,如float或scaled_float)date, ip和boolean。
度量标准聚合
此系列中的聚合基于从正在聚合的文档中以某种方式提取的值来计算度量标准。这些值通常从文档的字段中提取(使用字段数据),但也可以使用脚本生成。
数字度量标准聚合是一种特殊类型的度量标准聚合,可输出数值。一些聚合输出单个数字度量(例如avg)并被调用single-value numeric metrics aggregation,其他聚合生成多个度量(例如stats)并被调用multi-value numeric metrics aggregation。当这些聚合用作某些存储桶聚合的直接子聚合时,单值和多值数字度量聚合之间的区别起作用(某些存储桶聚合使您能够根据每个存储桶中的数字度量对已返回的存储桶进行排序)。
平均聚合
一种single-value度量聚合,用于计算从聚合文档中提取的数值的平均值。可以从文档中的特定数字字段提取这些值,也可以通过提供的脚本生成这些值。
假设数据由代表考试成绩(0到100)的学生组成,我们可以将他们的分数平均为:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}
上述聚合计算所有文档的平均成绩。聚合类型是avg,field设置定义将计算平均值的文档的数字字段。以上将返回以下内容:
{
...
"aggregations": {
"avg_grade": {
"value": 75.0
}
}
}
聚合的名称(avg_grade上面)也可以作为从返回的响应中检索聚合结果的密钥。
脚本
根据脚本计算平均成绩:
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"source" : "doc.grade.value"
}
}
}
}
}
这将使用脚本语言将script参数解释为脚本,而不使用脚本参数。要使用存储的脚本,请使用以下语法:inlinepainless
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
值脚本
事实证明,考试高于学生的水平,需要进行等级校正。我们可以使用值脚本来获得新的平均值:
POST /exams/_search?size=0
{
"aggs" : {
"avg_corrected_grade" : {
"avg" : {
"field" : "grade",
"script" : {
"lang": "painless",
"source": "_value * params.correction",
"params" : {
"correction" : 1.2
}
}
}
}
}
}
缺少价值
该missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /exams/_search?size=0
{
"aggs" : {
"grade_avg" : {
"avg" : {
"field" : "grade",
"missing": 10
}
}
}
}
在该grade字段中没有值的文档将与具有该值的文档属于同一个存储桶10。 |
|
|---|---|
加权平均聚合
一种single-value度量聚合,用于计算从聚合文档中提取的数值的加权平均值。可以从文档中的特定数字字段提取这些值。
在计算常规平均值时,每个数据点具有相等的“权重”……它对最终值的贡献相等。另一方面,加权平均值对每个数据点的权重不同。每个数据点对最终值的贡献量是从文档中提取的,或由脚本提供的。
作为一个公式,加权平均值是 ∑(value * weight) / ∑(weight)
常规平均值可以被认为是加权平均值,其中每个值具有隐含权重1。
表4. weighted_avg参数
| 参数名称 | 描述 | 需要 | 默认值 |
|---|---|---|---|
value |
提供值的字段或脚本的配置 | 需要 | |
weight |
提供权重的字段或脚本的配置 | 需要 | |
format |
数字响应格式化程序 | 可选的 | |
value_type |
关于纯脚本或未映射字段的值的提示 | 可选的 |
在value和weight每个领域的具体配置对象有:
表5. value参数
| 参数名称 | 描述 | 需要 | 默认值 |
|---|---|---|---|
field |
应从中提取值的字段 | 需要 | |
missing |
如果字段完全丢失则使用的值 | 可选的 |
表6. weight参数
| 参数名称 | 描述 | 需要 | 默认值 |
|---|---|---|---|
field |
应从中提取权重的字段 | 需要 | |
missing |
如果场地完全缺失则使用的重量 | 可选的 |
示例
如果我们的文档有一个"grade"包含0-100数字分数的"weight"字段,以及一个包含任意数字权重的字段,我们可以使用以下公式计算加权平均值:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
产生如下响应:
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}
虽然允许多个每字段值,但只允许一个权重。如果聚合遇到具有多个权重的文档(例如,权重字段是多值字段),则它将引发异常。如果遇到这种情况,则需要script为权重字段指定a ,并使用脚本将多个值组合成一个要使用的值。
该单个权重将独立应用于从value字段中提取的每个值。
此示例显示如何使用单个权重对具有多个值的单个文档进行平均:
POST /exams/_doc?refresh
{
"grade": [1, 2, 3],
"weight": 2
}
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
三个值(1,2和3)将作为独立值包含在内,所有这些值的权重均为2:
{
...
"aggregations": {
"weighted_grade": {
"value": 2.0
}
}
}
聚合返回2.0结果,与手工计算时的预期相符: ((1*2) + (2*2) + (3*2)) / (2+2+2) == 2
脚本
值和权重都可以从脚本而不是字段派生。举个简单的例子,下面将使用脚本在文档中添加一个等级和权重:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"script": "doc.grade.value + 1"
},
"weight": {
"script": "doc.weight.value + 1"
}
}
}
}
}
缺少值
该missing参数定义应如何处理缺少值的文档。默认行为是不同的value和weight:
默认情况下,如果value缺少该字段,则忽略该文档,并且聚合将移至下一个文档。如果该weight字段缺失,则假定其权重1(如正常平均值)。
可以使用以下missing参数覆盖这两个默认值:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade",
"missing": 2
},
"weight": {
"field": "weight",
"missing": 3
}
}
}
}
}
基数聚合
一种single-value度量聚合,用于计算不同值的近似计数。可以从文档中的特定字段提取值,也可以通过脚本生成值。
假设您正在为商店销售编制索引,并希望计算与查询匹配的已售产品的唯一数量:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}
响应:
{
...
"aggregations" : {
"type_count" : {
"value" : 3
}
}
}
精确控制
此聚合还支持以下precision_threshold选项:
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type",
"precision_threshold": 100
}
}
}
}
这些precision_threshold选项允许交换内存的准确性,并定义一个唯一的计数,低于该计数,计数预计接近准确。高于此值,计数可能会变得更加模糊。支持的最大值为40000,高于此数字的阈值将与阈值40000具有相同的效果。默认值为3000。 |
|
|---|---|
计数是近似
计算精确计数需要将值加载到哈希集并返回其大小。当处理高基数集和/或大值作为所需的内存使用时,这不会扩展,并且在节点之间传递那些每个分片集的需要将利用集群的太多资源。
此cardinality聚合基于 HyperLogLog ++ 算法,该算法基于值的哈希值计算,并具有一些有趣的属性:
- 可配置的精度,决定如何交换内存的准确性,
- 低基数集的精确度,
- 固定内存使用情况:无论是数十亿还是数十亿的唯一值,内存使用量仅取决于配置的精度。
对于精度阈值c,我们使用的实现需要大约c * 8字节。
下图显示了错误在阈值之前和之后的变化:
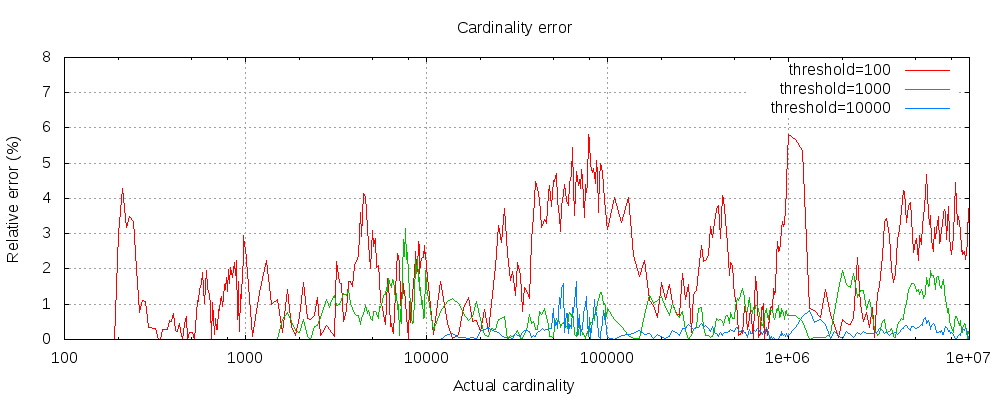
对于所有3个阈值,计数一直准确到配置的阈值。虽然不能保证,但可能就是这种情况。实践中的准确性取决于所讨论的数据集。通常,大多数数据集始终显示出良好的准确性。另请注意,即使阈值低至100,即使计算数百万个项目,误差仍然非常低(如上图所示为1-6%)。
HyperLogLog ++算法取决于散列值的前导零,数据集中散列的精确分布会影响基数的准确性。
另请注意,即使阈值低至100,即使计算数百万个项目,错误仍然非常低。
预先计算的哈希
在具有高基数的字符串字段上,将字段值的哈希值存储在索引中然后在此字段上运行基数聚合可能会更快。这可以通过从客户端提供哈希值或通过使用mapper-murmur3插件让Elasticsearch为您计算哈希值来完成 。
![]()
预计算哈希通常仅在非常大和/或高基数字段上有用,因为它节省了CPU和内存。但是,在数字字段上,散列非常快,并且存储原始值需要比存储散列更多或更少的内存。在低基数字符串字段中也是如此,特别是考虑到这些字段具有优化以确保每个段的每个唯一值最多计算一次哈希值。
脚本
该cardinality指标支持脚本编写,但是由于需要动态计算哈希值,因此会有明显的性能影响。
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script": {
"lang": "painless",
"source": "doc['type'].value + ' ' + doc['promoted'].value"
}
}
}
}
}
这将使用脚本语言将script参数解释为脚本,而不使用脚本参数。要使用存储的脚本,请使用以下语法:inlinepainless
POST /sales/_search?size=0
{
"aggs" : {
"type_promoted_count" : {
"cardinality" : {
"script" : {
"id": "my_script",
"params": {
"type_field": "type",
"promoted_field": "promoted"
}
}
}
}
}
}
缺少价值
该missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
POST /sales/_search?size=0
{
"aggs" : {
"tag_cardinality" : {
"cardinality" : {
"field" : "tag",
"missing": "N/A"
}
}
}
}
在该tag字段中没有值的文档将与具有该值的文档属于同一个存储桶N/A。 |
|
|---|---|
扩展统计聚合编辑
一种multi-value度量聚合,用于计算从聚合文档中提取的数值的统计信息。可以从文档中的特定数字字段提取这些值,也可以通过提供的脚本生成这些值。
所述extended_stats聚合是的扩展版本stats聚集,其中附加的度量被加到如sum_of_squares,variance,std_deviation和std_deviation_bounds。
假设数据由代表考试成绩(0到100)的学生组成
GET /考试/ _search
{
“大小”:0,
“aggs”:{
“grades_stats”:{“extended_stats”:{“field”:“grade”}}
}
}
上述聚合计算所有文档的成绩统计。聚合类型是extended_stats,field设置定义将在其上计算统计数据的文档的数字字段。以上将返回以下内容:
{
...
“聚合”:{
“grades_stats”:{
“数”:2,
“min”:50.0,
“max”:100.0,
“avg”:75.0,
“总和”:150.0,
“sum_of_squares”:12500.0,
“差异”:625.0,
“std_deviation”:25.0,
“std_deviation_bounds”:{
“鞋面”:125.0,
“更低”:25.0
}
}
}
}
聚合的名称(grades_stats上面)也可以作为从返回的响应中检索聚合结果的密钥。
标准偏差界限编辑
默认情况下,extended_stats度量标准将返回一个名为的对象std_deviation_bounds,该对象提供与均值相差两个标准差的区间。这可以是一种可视化数据方差的有用方法。如果您想要一个不同的边界,例如三个标准偏差,您可以sigma在请求中进行设置:
GET /考试/ _search
{
“大小”:0,
“aggs”:{
“grades_stats”:{
“extended_stats”:{
“场”:“等级”,
“西格玛”:3
}
}
}
}
sigma 控制应显示平均值+/-的标准偏差 |
|
|---|---|
sigma可以是任何非负的双精度,意味着您可以请求非整数值,例如1.5。值为0有效,但只返回两者upper和lower边界的平均值。
![]()
标准偏差和界限需要正常性
默认情况下会显示标准偏差及其边界,但它们并不总是适用于所有数据集。您的数据必须正常分发才能使指标有意义。标准偏差背后的统计数据假设是正态分布的数据,因此如果您的数据严重偏向左或右,则返回的值将会产生误导。
脚本编辑
根据脚本计算成绩统计:
GET /考试/ _search
{
“大小”:0,
“aggs”:{
“grades_stats”:{
“extended_stats”:{
“script”:{
“来源”:“doc ['grade']。value”,
“郎”:“无痛”
}
}
}
}
}
这将使用脚本语言将script参数解释为脚本,而不使用脚本参数。要使用存储的脚本,请使用以下语法:inlinepainless
GET /考试/ _search
{
“大小”:0,
“aggs”:{
“grades_stats”:{
“extended_stats”:{
“script”:{
“id”:“my_script”,
“params”:{
“场”:“等级”
}
}
}
}
}
}
值脚本编辑
事实证明,考试高于学生的水平,需要进行等级校正。我们可以使用值脚本来获取新的统计信息:
GET /考试/ _search
{
“大小”:0,
“aggs”:{
“grades_stats”:{
“extended_stats”:{
“场”:“等级”,
“script”:{
“郎”:“无痛”,
“source”:“_ value * params.correction”,
“params”:{
“纠正”:1.2
}
}
}
}
}
}
缺少价值编辑
该missing参数定义应如何处理缺少值的文档。默认情况下,它们将被忽略,但也可以将它们视为具有值。
GET /考试/ _search
{
“大小”:0,
“aggs”:{
“grades_stats”:{
“extended_stats”:{
“场”:“等级”,
“失踪”:0
}
}
}
}
在该grade字段中没有值的文档将与具有该值的文档属于同一个存储桶0。 |
|
|---|---|
地理边界聚合编辑
一种度量聚合,用于计算包含字段的所有geo_point值的边界框。
例:
PUT /博物馆
{
“映射”:{
“properties”:{
“地点”: {
“type”:“geo_point”
}
}
}
}
POST / museums / _bulk?刷新
{ “索引”:{ “_编码”:1}}
{“location”:“52.374081,4.912350”,“name”:“NEMO Science Museum”}
{ “索引”:{ “_编码”:2}}
{“location”:“52.369219,4.901618”,“name”:“Museum Het Rembrandthuis”}
{ “索引”:{ “_ ID”:3}}
{“location”:“52.371667,4.914722”,“name”:“Nederlands Scheepvaartmuseum”}
{ “索引”:{ “_ ID”:4}}
{“location”:“51.222900,4.405200”,“name”:“Letterenhuis”}
{ “索引”:{ “_编码”:5}}
{“location”:“48.861111,2.336389”,“name”:“MuséeduLouvre”}
{ “索引”:{ “_ ID”:6}}
{“location”:“48.860000,2.327000”,“name”:“Muséed'Orsay”}
POST / museums / _search?size = 0
{
“查询”:{
“匹配”:{“name”:“musée”}
},
“aggs”:{
“viewport”:{
“geo_bounds”:{
“field”:“location”,
“wrap_longitude”:是的
}
}
}
}
该geo_bounds集合指定现场使用,以获得界限 |
|
|---|---|
wrap_longitude是一个可选参数,指定是否允许边界框与国际日期行重叠。默认值为true |
上面的聚合演示了如何计算具有商店类型商店的所有文档的位置字段的边界框
上述聚合的响应:
{
...
“聚合”:{
“viewport”:{
“bounds”:{
“左上方”: {
“lat”:48.86111099738628,
“lon”:2.3269999679178
},
“bottom_right”:{
“lat”:48.85999997612089,
“lon”:2.3363889567553997
}
}
}
}
}
Geo Centroid Aggregationedit
A metric aggregation that computes the weighted centroid from all coordinate values for a Geo-point datatype field.
Example:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "city": "Amsterdam", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "city": "Amsterdam", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "city": "Amsterdam", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "city": "Antwerp", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "city": "Paris", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "city": "Paris", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"aggs" : {
"centroid" : {
"geo_centroid" : {
"field" : "location"
}
}
}
}
The geo_centroid aggregation specifies the field to use for computing the centroid. (NOTE: field must be a Geo-point datatype type) |
|
|---|---|
The above aggregation demonstrates how one would compute the centroid of the location field for all documents with a crime type of burglary
The response for the above aggregation:
{
...
"aggregations": {
"centroid": {
"location": {
"lat": 51.00982965203002,
"lon": 3.9662131341174245
},
"count": 6
}
}
}
The geo_centroid aggregation is more interesting when combined as a sub-aggregation to other bucket aggregations.
Example:
POST /museums/_search?size=0
{
"aggs" : {
"cities" : {
"terms" : { "field" : "city.keyword" },
"aggs" : {
"centroid" : {
"geo_centroid" : { "field" : "location" }
}
}
}
}
}
The above example uses geo_centroid as a sub-aggregation to a terms bucket aggregation for finding the central location for museums in each city.
The response for the above aggregation:
{
...
"aggregations": {
"cities": {
"sum_other_doc_count": 0,
"doc_count_error_upper_bound": 0,
"buckets": [
{
"key": "Amsterdam",
"doc_count": 3,
"centroid": {
"location": {
"lat": 52.371655656024814,
"lon": 4.909563297405839
},
"count": 3
}
},
{
"key": "Paris",
"doc_count": 2,
"centroid": {
"location": {
"lat": 48.86055548675358,
"lon": 2.3316944623366
},
"count": 2
}
},
{
"key": "Antwerp",
"doc_count": 1,
"centroid": {
"location": {
"lat": 51.22289997059852,
"lon": 4.40519998781383
},
"count": 1
}
}
]
}
}
}